GitHub: nchah/word2vec4everything
Or, word2vec for (almost) everything.
This is a project where I process some interesting text documents through the word2vec machine learning model and visualize the resulting vectors to discover any interesting relationships and clusters that may come up.
Introduction to word2vec
As explained on Wikipedia, word2vec refers to a number of machine learning models that take a corpus of text and output a vector space of word embeddings. The word2vec model was created at Google by a team of Tomas Mikolov et al. in 2013 and has since been adapted in numerous papers. The resulting word vectors can be visualized in such a way that words with similar semantic meanings and contexts are clustered together. As an unsupervised machine learning technique, the input text that is fed into the word2vec model doesn’t require any labels. This makes it all the more interesting when the final vector visualizations show that semantically related words are clustered together.
The t-distributed Stochastic Neighbor Embedding (t-SNE) technique is used to visualize the final word2vec embeddings onto a 2-dimensional space. This step is necessary as the multi-dimensional vectors can’t be shown in either 2-D or 3-D space.
Dependencies
This project implements word2vec using Google’s TensorFlow library.
- Python 2.x
- TensorFlow
- Plenty of other libraries: matplotlib, nltk, and sklearn, etc.
The TensorFlow scripts in the python directory are modifications to the starter code provided in the TensorFlow tutorials: Vector Representations of Words. The modifications I’ve made include:
- Python PEP8 styling changes
- General refactoring
- Further code to adjust the visualization step
Running on the command line is as simple as
$ python python/word2vec4everything-basic.py --input_data=path/to/data
Gallery
These are a selection of the most interesting visualizations that have been produced by word2vec4everything. This project is somewhat limited by the public availability of texts on the Internet. 🙂
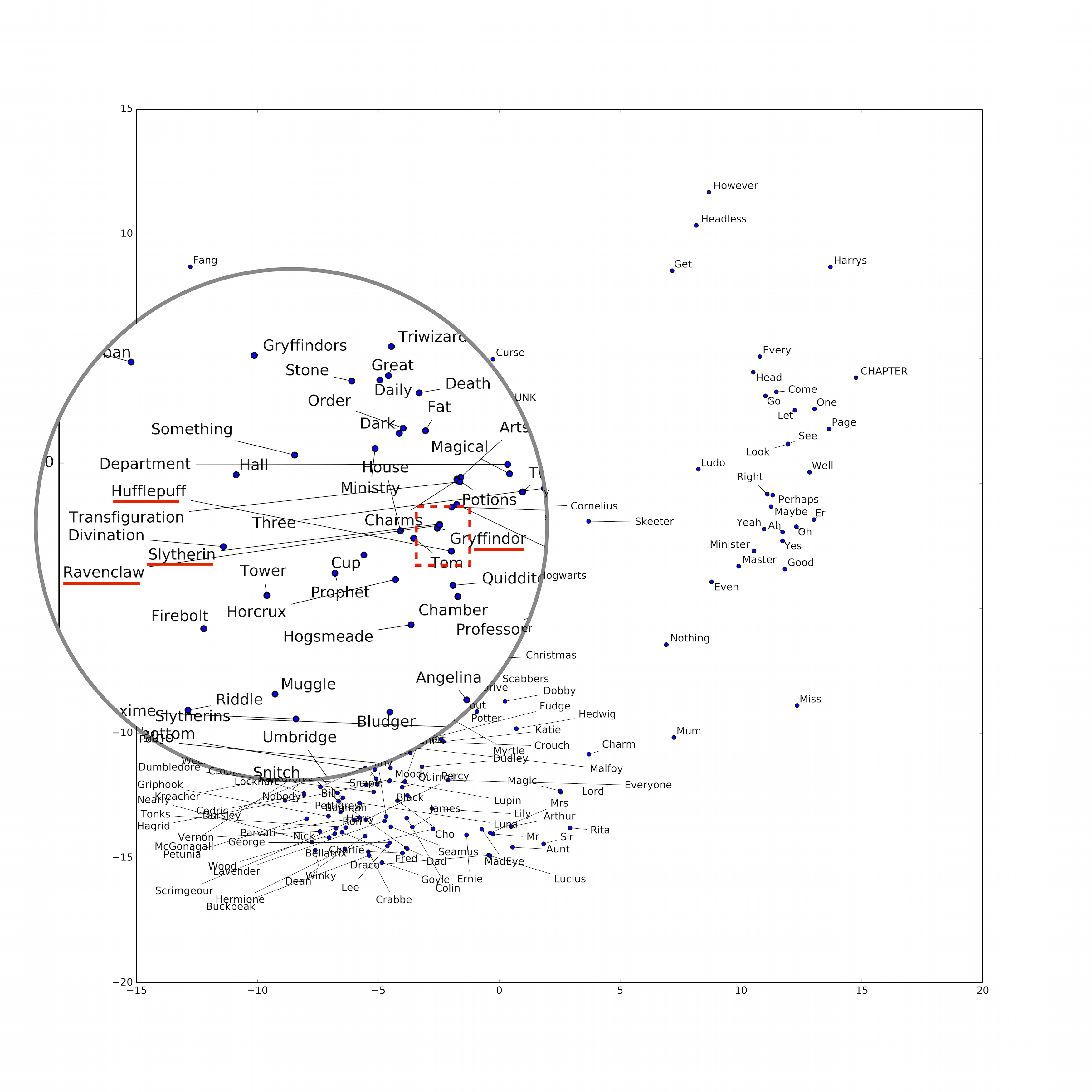
All 7 Harry Potter books
- Data: ~10 MB – A plaintext file of all 7 Harry Potter books. Found with the help of some Google-fu.
- Comment: word2vec clusters the 4 houses of Hogwarts (Gryffindor, Hufflepuff, Ravenclaw, and Slytherin) together.
The Fellowship of the Ring
- Data: ~1 MB – A plaintext file of the first book in The Lord of the Rings book series.
- Comment: word2vec clusters the members of the Fellowship of the Ring: Frodo, Sam, Gandalf, Legolas, Gimli, Aragorn, Boromir, Merry, and Pippin. It’s also neat that ‘Strider’ is quite close to Aragorn. Sauron, Saruman, and Gollum are also relatively distant from the Fellowship.
The Bible, King James version
- Data: ~4.4 MB – A plaintext file of the Bible, King James version.
- Comment: There seems to be a distinct cluster for the ‘God’ related words and a separate cluster for the prominent people in the source text. Running the script again seems to replicate this interesting finding.
The Chronicles of Narnia
- Data: ~1.7 MB – A plaintext file of all books in the Chronicles of Naria.
- Comment: Aslan, an important character in the series, seems to be an outlier from the cluster of other main characters. However, replicating this in other iterations doesn’t quite support this as strongly.